
Don’t believe the model, don’t ignore the model
Analogieën voor het testproces
Een goede raad: don’t believe the model: de werkelijkheid is altijd anders, rijker, gedetailleerder, genuanceerder en veelkleuriger. Nog een goede raad: don’t ignore the model, want goede modellen doen uitspraken over een stukje van de werkelijkheid, uitspraken die in veel gevallen waar zijn.
Vooral de combinatie van deze adviezen is waardevol: zonder het eerste advies is de verleiding groot het tweede in te korten tot: ‘modellen doen uitspraken over de werkelijkheid die waar zijn’. Samen geven ze het evenwicht dat het mogelijk maakt beschikbare modellen te onderzoeken en ze zinvol toe te passen als de situatie zich daarvoor leent.
Zoals de IT haar eigen modellen kent zo kennen ook andere disciplines hun eigen modellen. Dat zijn modellen die uitspraken doen die we niet zonder meer mogen vertalen naar ons vakgebied. Als we echter rekening houden met het ‘don’t believe’, dan kunnen we er op een verantwoorde manier van profiteren.
De complexiteit van applicaties groeit door functionaliteittoename en door de verhoging van kwaliteitseisen als beschikbaarheid en responsetijd. De testinspanning neemt toe met de complexiteit en is inmiddels zo groot dat het testen van applicaties een cruciaal onderdeel van het ontwikkelproces is. De kosten van systeemontwikkeling en de time-to-market zijn in hoge mate afhankelijk van de kwaliteiten van het testproces. Dit is al een probleem als het om de ‘test voor implementatie’ gaat die volgt op het initiële ontwerp en de bouw, en wordt vergroot door het tempo waarin de business en de technologie veranderen. Applicaties worden daardoor frequent en ingrijpend gewijzigd, waarna ze weer getest moeten worden. Reden genoeg om eens te kijken of er modellen zijn die hierbij kunnen helpen.
Hypothesen
Het eerste model is natuurlijk het algemene model waarlangs de huidige wetenschap zich ontwikkelt: op basis van deductie of inductie wordt een hypothese geformuleerd, vervolgens worden experimenten ingericht om deze te toetsen, waarna de hypothese ongewijzigd blijft, op punten wordt aangepast of geheel wordt verworpen, afhankelijk van de uitkomst van het experiment.
Hierin zitten enkele leuke analogieën. Dat een hypothese een systeem is en vice versa, is nauwelijks een analogie; dat is meer een gegeven. Dat bij het onderscheid deductie/inductie een parallel getrokken kan worden naar meer vanuit de IT versus meer vanuit de business geïnitieerde systemen is aardig, maar biedt geen aanknopingspunt voor het testproces. Dat hypothesen naar huidige inzichten door experimenten slechts gefalsificeerd kunnen worden en niet gevalideerd, komt overeen met het algemene inzicht dat door testen wel het onjuist zijn van een systeem kan worden aangetoond, maar nimmer de juistheid. En net als in de wetenschap gaan we er na een eerste grondige toetsing van uit dat de hypothese waar is tot het tegendeel wordt aangetoond.
Helaas moet dus geconstateerd worden dat hoewel de analogie treffend is, dit model ons weinig concreets biedt om testprocessen te verbeteren.
De huisarts
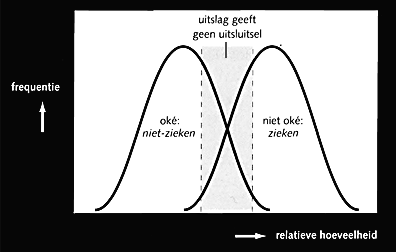
Een analogie die ons misschien verder kan helpen, is die van de huisarts en de patiënt: de patiënt als te testen systeem en de huisarts als tester. In de medische praktijk komen tests voor waarbij spra-e is van een gedeeltelijke overlap van testuitslagen die ‘oké’ en ‘niet oké’ suggereren. Grafisch weergegeven ziet dat eruit als in figuur 1: de uitslag (bijvoorbeeld de relatieve hoeveelheid van een bepaalde stof in het bloed) bij personen die de ziekte niet hebben overlapt voor een deel de uitslag van personen die de ziekte wel hebben.
Een onoplosbaar probleem binnen de context van de test is het trekken van de grens gezond/ziek. Trek je die te veel naar links dan verklaar je daarmee gezonde mensen ziek, trek je de grens te veel naar rechts, dan verklaar je zieke mensen gezond. Maar hoe je de grens ook trekt, als de grafieken overlappen is er altijd een deel waarover je geen uitspraak kunt doen. Wat overblijft is nader onderzoek: verder testen. Medici hanteren de regel dat er alleen onderzoek wordt verricht als op voorhand duidelijk is dat de uitslag relevant is voor het vervolg van de behandeling. Dat betekent dat vooraf vaststaat wat zal worden gedaan bij de verschillende mogelijke testuitslagen.
Relateren we dit aan onze eigen testpraktijk, dan kunnen verschillende eisen worden onderscheiden waarop we testen. Aan de eisen die worden gesteld, wordt voldaan — of niet. Een programma dat twee getallen bij elkaar optelt doet dat goed (7 plus 8 geeft 15) of niet (2 plus 3 geeft 6). In het laatste geval hebben we aangetoond dat het programma niet juist werkt. In termen van figuur 1 hebben we dan twee grafieken die niet overlappen. Het vooraf vaststellen van te nemen acties bij ‘oké’ en ‘niet oké’ is eenvoudig: als de applicatie niet voldoet aan de eis wordt zij aangepast, en dat net zo vaak als nodig is.
Er zijn ook eisen die goed gekwantificeerd kunnen worden, maar waarvan het moeilijker is om vast te stellen of eraan voldaan wordt. Een voorbeeld: ‘de responsetijd moet in 95 procent 3 seconden of minder zijn’. Vaststellen dat aan deze eis al dan niet wordt voldaan, wordt al moeilijker. Wat als tijdens de eerste meting in productie duizend transacties verwerkt zijn waarvan 94 procent een responsetijd had van minder dan 2 seconden en 6 procent een responsetijd van 3,1 seconde? Als de eerste meting karakteristiek is voor het gedrag van het systeem, is het evident dat aan de geformuleerde eis niet wordt voldaan. Tegelijkertijd is het zeer aannemelijk dat aan de bedoeling van degene die de eis heeft geformuleerd wel is voldaan (of denkt u dat 95 procent in 3 seconden en 5 procent in 15 seconden tot een grotere tevredenheid zou leiden?)
Een derde categorie eisen is nog moeilijker kwantificeerbaar. Elk voorbeeld is discutabel, maar laten we even aannemen dat gebruikersvriendelijkheid in die categorie valt: een in wezen subjectief oordeel moet dan worden geobjectiveerd. De uitslag zal overeenkomsten vertonen met figuur 1: de kans dat een testgroep een gebruikersvriendelijke applicatie tot ‘niet gebruikersvriendelijk’ verklaart, is aanwezig. Bij dergelijke tests waarbij ‘oké’ en ‘niet oké’ elkaar overlappen, voorkomt het vooraf definiëren van de vervolgactie onnodige tests (namelijk daar waar ongeacht de uitslag, toch geen vervolgactie plaatsvindt). Daarnaast geldt dat het proces van het formuleren van vervolgacties bij bepaalde testuitslagen waarschijnlijk eenvoudiger is zolang de testuitslagen nog niet bekend zijn.
Figuur 1
De analogie met de huisarts biedt al met al wel een paar aanknopingspunten, maar de verschillen tussen de testpraktijk van de huisarts en onze testpraktijk zijn zo groot dat de bruikbaarheid van de analogie toch beperkt is. Anders wordt dat als we de stap maken van organische naar mechanische systemen.
De garage
De analogie waar we het meest aan hebben, is wellicht die van de garage als tester en de auto als te testen systeem. Dat is geen erg wetenschappelijk model, maar het heeft wel veel aanknopingspunten met de IT-praktijk. Als mijn auto een probleem vertoont, dan heeft de monteur daar hulpmiddelen voor. Op het eerste gezicht verschilt dit niet van de situatie bij een huisarts, die heeft immers ook hulpmiddelen. Het grote verschil is echter dat mijn auto ook hulpmiddelen heeft: de kabel van de testapparatuur van de garage past ergens onder de motorkap van mijn auto, en terwijl de monteur vraagt of ik zin heb in een kopje koffie, worden allerlei tests uitgevoerd.
Complexiteit
Complexiteit van een applicatie kan worden onderscheiden in statische en dynamische complexiteit. De statische complexiteit is groter naarmate de applicatie groter is. De complexiteittoename heeft over het algemeen een niet-lineair verband met de omvang van een applicatie, doordat het aantal relaties tussen de componenten waaruit een applicatie bestaat sneller toeneemt dan het aantal componenten zelf. De dynamische complexiteit is groter naarmate het aantal toestandsveranderingen dat zich kan voordoen groter is, en hangt dus nauw samen met de verschillende soorten gebeurtenissen en de mogelijke samenhang daartussen. Ook toenemende kwaliteitseisen kennen niet-lineaire verbanden. Het verbeteren van bijvoorbeeld de beschikbaar-heid van een applicatie of het terugbrengen van de responsetijd lijkt op ‘harder fietsen’: vijftien kilometer per uur gaat als vanzelf, het verhogen naar vijfentwintig kilometer kost merkbaar energie maar lukt nog wel, maar op de een of andere manier is vijftig kilometer per uur fietsen voor de meesten onbereikbaar. Van 80 procent naar 90 procent beschikbaarheid van een applicatie is over het algemeen geen punt, maar 100 procent is letterlijk onbereikbaar. De maatregelen die noodzakelijk zijn om aan hogere kwaliteitseisen te voldoen leiden altijd tot een verhoging van de complexiteit van de applicatie zelf en/of de exploitatie-omgeving ervan.
Beperken en beheersen
Complexiteit is enerzijds intrinsiek, noodzakelijk, en wordt bepaald door de eisen waaraan een applicatie moet voldoen. Complexiteit is anderzijds wat we waarnemen, wat feitelijk aanwezig is. De waargenomen complexiteit kan groter zijn dan de intrinsieke complexiteit door een slecht ontwerp, slecht
onderhoud of een slechte keuze van de technische omgeving waarin een applicatie operationeel is. Beperking van complexiteit is primair een zaak van overleg tussen business en IT: beperk de eisen en wensen tot dat, wat ook werkelijk nodig is, wat zinvol kan worden gebruikt.
Beheersing van complexiteit is een verantwoordelijkheid van de IT. Zonder een definitie waarmee complexiteit gekwantificeerd kan worden, is geen antwoord mogelijk op de vraag of de waargenomen complexiteit ook kleiner kan zijn dan de intrinsieke complexiteit, of dat zij daaraan minimaal gelijk moet zijn. Wat zeker is, is dat een goed ontwerp (ondersteund door de juiste ontwikkeltoois) en een goed ingerichte exploitatieomgeving een groot verschil uitmaken in de feitelijk aanwezige complexiteit.
Dus...
Testen is niet iets dat na de bouw komt. De systemen zijn zo complex dat al bij het ontwerp ervan rekening moet worden gehouden met het feit dat er getest moet worden. Dit moet worden vertaald in aandacht voor complexiteit die, voor zover mogelijk, beperkt en beheerst wordt. Voor het overige is het een gegeven en moeten we systemen testbaar bouwen, en moeten er behalve het systeem zelf ook systemen ontwikkeld worden om het systeem te testen: de testapparatuur in de garage is ‘hand in hand’ met de te testen auto’s ontwikkeld!
De andere modellen leren ons wat we al wisten: dat een systeem nooit foutloos is, met als consequentie dat we de processen om fouten op te lossen goed moeten inrichten. Ze leren ons ook dat het goed is om vooraf na te denken over waarom wat getest moet worden, en over wat we met de uitslag van de test moeten doen.
